[TOC]
imagine you are a big-shot business with terabytes of customer-driven data: text, images, videos, audio. you want to use this data to improve your business, maybe for *a new targeting system*, a new *active learning feature*, *recommendation* sales, or for *moderation* - whatever the reason, you need to label this data first
it is not enough to have a review for your product; you also need to know whether this review is negative or positive, and what kind of sentiments the review represents. does the image show a cat or a dragon's butt? it is very important when your business is based on accuracy, and you are trying to sell subscriptions or products
that's where labeling comes in
!!!info Q. *labe**l**ing or labe**ll**ing?*
same stuff.
- USA prefers "[labeling](https://en.wiktionary.org/wiki/labeling)" because that country is allergic to multiple same-y letters in a row
- all the rest of the world loves [them labels having lots of Ls](https://en.wiktionary.org/wiki/labelling)
***
# outsourcing data labeling
labeling *millions of files* by yourself is ridiculous, no one has the time or nerves for it. thankfully, we have services like [Amazon Mechanical Turk](https://en.wikipedia.org/wiki/Amazon_Mechanical_Turk), allowing any company **to outsource intellectual labor to external workers** for a small (*for them*) fee. of course, if you are Google and control 628% of the internet, then you can just [outsource labeling to random users on the internet for free and call it reCAPTCHA](https://research.aimultiple.com/data-labeling-outsourcing/), but most companies are not afforded this luxury and have no option but to pay some random guy in a random country to label your random piece of data
it comes with **downsides**:
1) you are sharing your private data with an external worker who will read it, memorize it, and maybe even copy it
2) you are sharing customer/user-generated content in the first place, some privacy aspects are affected as well
3) you cannot be 100% sure that the labeling will be top-quality; human errors are bound to happen and margin of error must be assumed
in cases when privacy and quality of labeling are of the utmost importance, then you might hire specialists from data-labeling firms, but such companies come with **downsides of their own**:
1) they are more expensive
2) they try to sell you on their services - to force you to subscribe to their tech stack and workflow integration
3) they sound extremely cool on paper, showcasing their data specialists and experience in various fields, while they are *really* the same random guys in random countries
oh welp we didn't know any better
...until 2023 **and LLM boom happened**
***
# human-driven labeling is dead
nowadays if you have 627,256,272 text segments that need classifying, then in 99% of cases, AI will do it (with an optional half-assed human reviewer). companies have shifted away from human-powered labor, embracing AI-driven labeling systems instead. the above-mentioned [Snorkel](https://snorkel.ai/snorkel-flow/) doesn't sugarcoat it:
> Labeled data is required to train highly accurate AI/ML models for specialized, domain-specific tasks. However, **manual data labeling with human annotation is slow, expensive**, and often blocks enterprise AI projects on day one. AI data development eliminates this bottleneck by streamlining collaboration between data scientists and SMEs via [...blah blah blah]
even companies well-known for their human-driven labeling, like [Labelbox](https://labelbox.com/pricing/calculator/), stress in their docs:
> [...you pay for] within your labeling project: 1) a human generated **label or model** prediction is approved as a ground truth label *by a reviewer*; or 2) the data row is marked as ‘done’ (without review) in the labeling workflow
and this trend isn't limited to these ""small"" companies. even industry leaders, like Google, no longer provide human-assisted labeling as a service. back in 2020, they proudly launched the **data labeling service** [feature on their AI Platform](https://cloud.google.com/vertex-ai/docs/datasets/data-labeling-job). Google's laborers were equipped to handle a wide array of tasks: sentiment analysis, data classification, entity identification, etc. in 2022, they closed AI Platform and migrated the data labeling service over to Vertex AI, only to [discontinue labeling entirely in mid-2023](https://colab.research.google.com/github/GoogleCloudPlatform/vertex-ai-samples/blob/main/notebooks/official/datasets/get_started_with_data_labeling.ipynb):
> **Vertex AI Data Labeling Service** (requesting human labelers) **is deprecated** and will no longer be available on Google Cloud after July 1, 2024. For new labeling tasks, you can add labels using the Google Cloud console or access data labeling solutions from our partners in the Google Cloud Console Marketplace
if you try to access [Vertex AI's page about human labelers](https://cloud.google.com/vertex-ai/docs/datasets/data-labeling-job) - you will be redirected to the [page about how to label data yourself](https://cloud.google.com/vertex-ai/docs/datasets/label-using-console) or via AI; use Wayback Machine [to access it](https://web.archive.org/web/20210618070309/https://cloud.google.com/vertex-ai/docs/datasets/data-labeling-job). oddly enough, human-annotated labeling is still listed [on Vertex AI's pricing page](https://cloud.google.com/vertex-ai/pricing#labeling), which proves Google has no fucking clue what they list in their own docs
so why is this shift happening? why are companies moving from humans to AI? why is **human-driven data labeling dead**?
{{{D-marginMid /D}}}
{{{D-inline-highlight-red-center money /D}}}
{{{D-marginMid /D}}}

***
# AI-labeling is super cheap
AI makes labeling so cheap it is not even remotely comparable to prices for human annotation
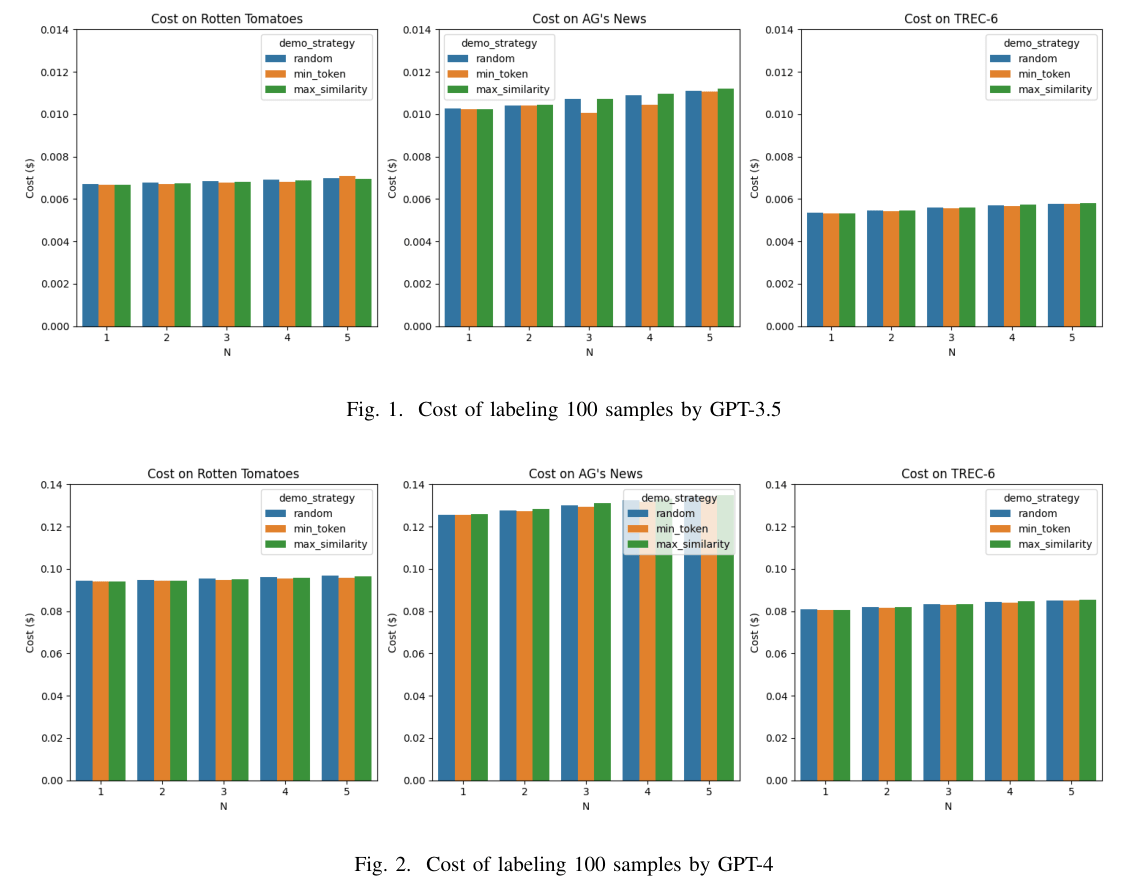
"[**Want To Reduce Labeling Cost? GPT-3 Can Help**](https://arxiv.org/abs/2108.13487)" is a 2021 paper by Wang, Liu, Xu, Zhu, Zeng. it is *one of the most well-known papers on this subject* (cited more than 200 times!). authors did some rough estimation and drew a conclusion that on average, three-shot GPT-3 prompting cost them **~$0.061 versus a human's ~$0.84: ten times cheaper**. as for performance - GPT-3 reached the same performance as humans on multiple NLU and NLG tasks. that paper opened the door for more experimentation, workflow optimization, and nuances of how to lower costs even further. and please do keep in mind that *this is a paper from 2021* and GPT-3 was the best thing back then. current models cost even less and more reliable
in summer 2023 paper "[**Automated Annotation with Generative AI Requires Validation**](https://arxiv.org/abs/2306.00176)" Pangakis, Wolken, Fasching estimated that it cost them only **~$420 to label 200,000 text samples via GPT-4**. which is insane! and again, do note it was *summer 2023*: before *GPT-4 Turbo* (cheaper), before *GPT-4o* (even cheaper), and before *GPT-4o-mini* (so cheap even China buys it)
Wang in "[**Active Learning for NLP with Large Language**](https://arxiv.org/abs/2401.07367)" paper from 2024 states that it cost **$0.08 - $0.10** to label 100 text fragments via GPT-4, but the same task done via human annotator cost **~$11 - $12**. quoting:
> ...the labeling cost by GPT-3 is about 1/1000 of human annotations. And the cost of GPT-4 is about 10 times of GPT-3.5
***
# Vertex AI: price of human labor vs AI
lets break down simple math for a average corpo client
imagine we have got thousands of tweets, **2,000,000,000 words** in total. our goal is to label these tweets for hate speech, NSFW content, and spam - pretty generic task. how much would this cost using Google's human-based labeling service? we will use their [old pricing rules](https://cloud.google.com/vertex-ai/pricing#labeling) on Vertex AI. and if you think *those* rules are complicated, you haven't seen [the previous version of that pricing page](https://web.archive.org/web/20200428044537/https://cloud.google.com/ai-platform/data-labeling/pricing)
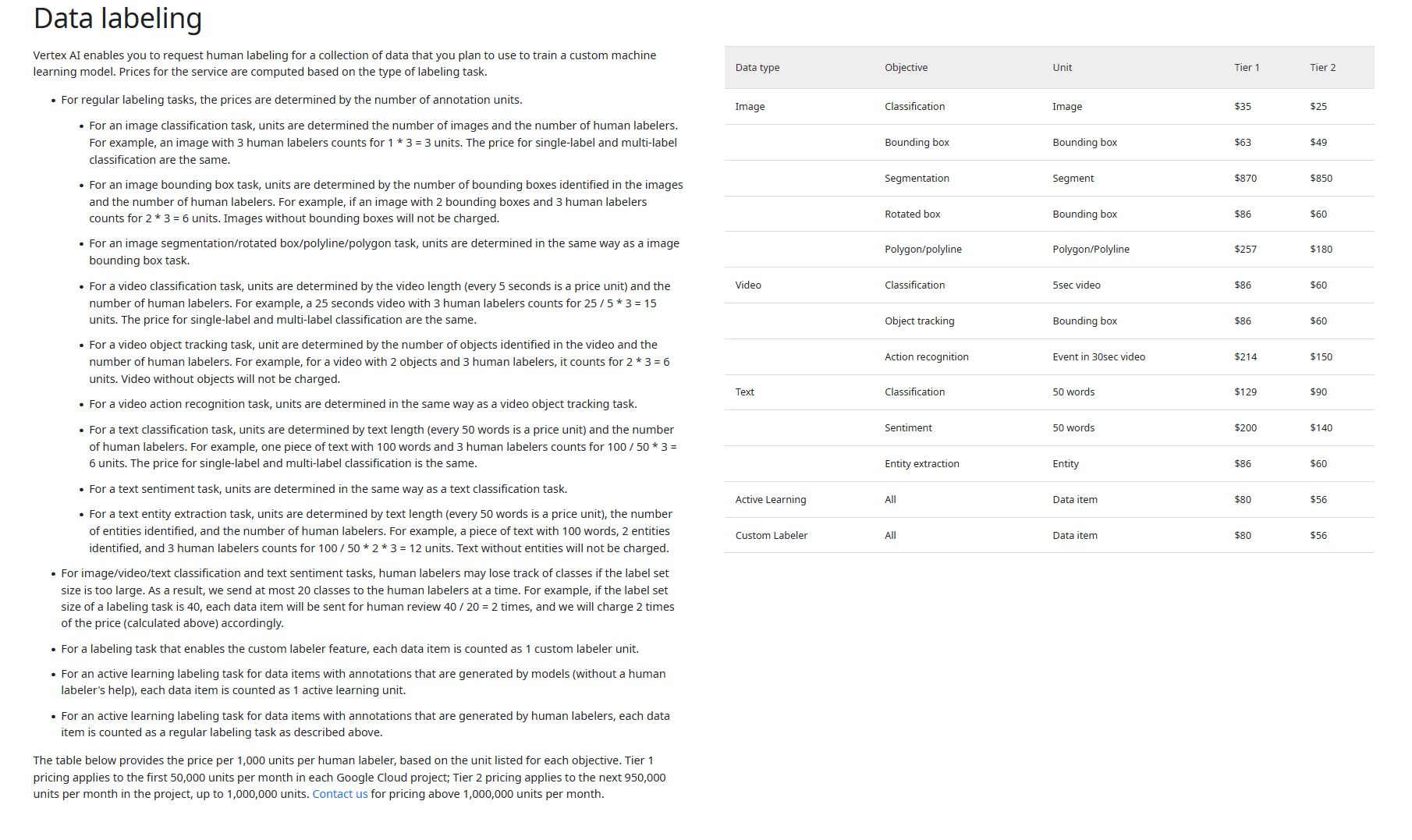
first, we should convert our data into `units` (*that's Google's local currency for labeling*). they say:
> For a text classification task, units are determined by text length (**every 50 words is a price unit**) and the number of human labelers. For example, one piece of text with 100 words and 3 human labelers counts for 100 / 50 * 3 = 6 units.
alright, makes sense. we are feeling cocky and hire two labelers. so, **2,000,000,000 / 50 * 2** gives us `80,000,000 units`
now for the price. they state that for our use case:
> The table below provides the **price per 1,000 units** per human labeler, based on the unit listed for each objective. Tier 1 pricing applies to the **first 50,000 units** per month in each Google Cloud project; Tier 2 pricing applies to the next 950,000 units per month in the project, up to 1,000,000 units.
Tier 1 - **$129**
Tier 2 - **$90**
we take **80,000,000 / 1,000**, which equals `80,000 units`
now for fancy math: **$129 * 50,000 + $90 * 30,000**, and that equals `$9,150,000`
{{{S-inline-highlight-red-underline **that is a lot!** /S}}}
***
compare that price to [Google Gemini 1-5 Flash](https://ai.google.dev/pricing#1_5flash) model:
- input pricing - **$0.075 / 1 million tokens**
- output pricing - **$0.30 / 1 million tokens**
2,000,000,000 english words is roughly `1,800,000,000` tokens, leading to:
- **1,800,000,000 / 1,000,000 * $0.075** = `$135 for input`
as for output, lets assume: 5 reply tokens per every 200 words. the math would be:
- **2,000,000,000 / 200 * 5 / 1,000,000 * $0.30** = `$15 for output`
if we consider system prompts, three extra shots, some experiments with prompt engineering, and running each evaluation five times for self-consistency: **($135 + $15) * 5 * 1.5** = `$1,050`
compare **$1,050 to $9,150,000**, and you can clearly see **why no one is using human labeling these days**
even if you take the best (most expensive) Google Model - [Gemini Pro 1-5](https://ai.google.dev/pricing#1_5pro) with prices **$1.25 and $5**, the customer would still pay `~$20,000`, which is, again, **TIMES cheaper than using human labor**